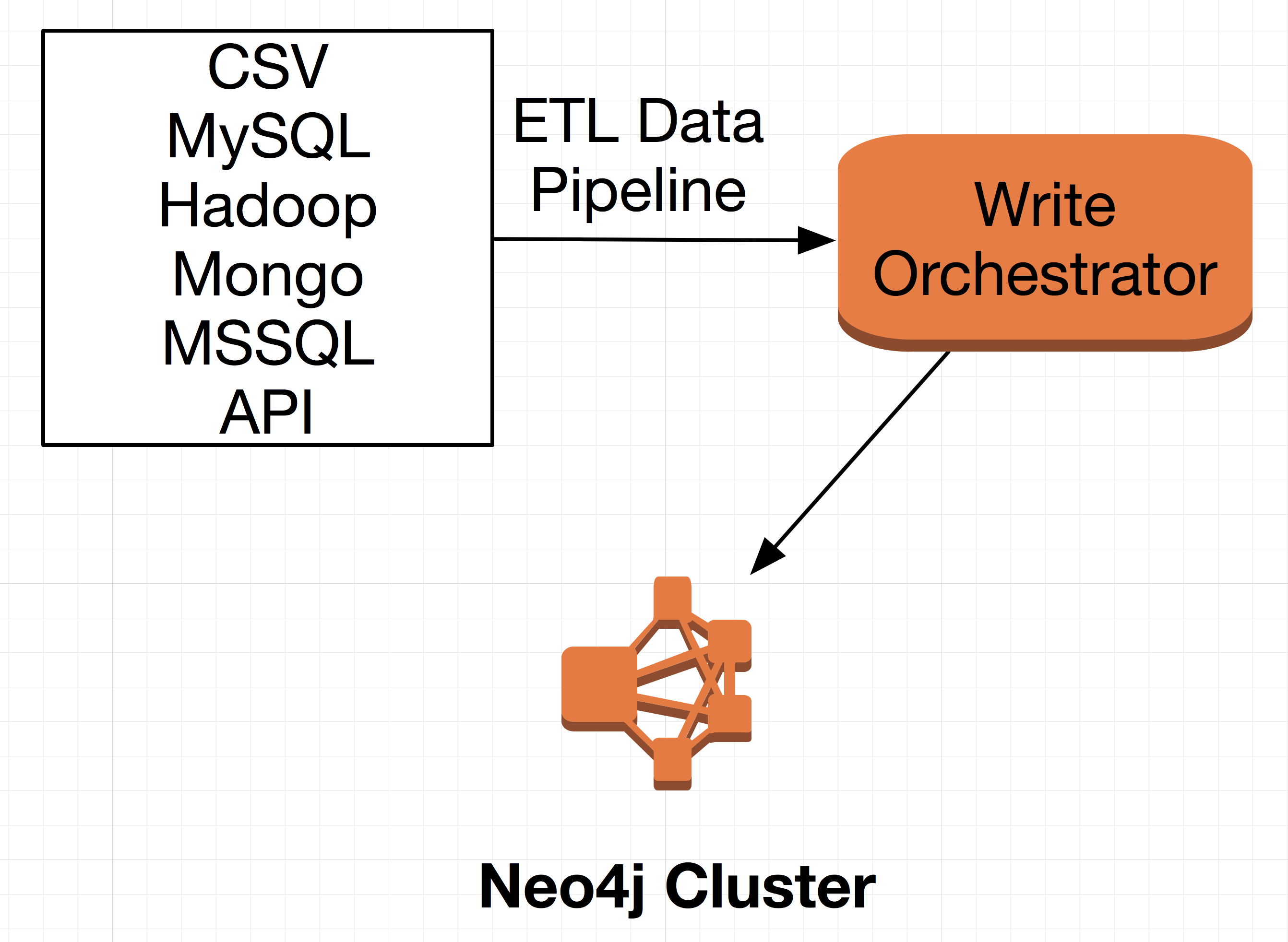
As organizations adopt graph databases, their available connected data will grow, which will drive the need for analytics to leverage the connected data as a core component of their analysis. The key to unlocking new insights is to leverage the connectedness of the data as part of a graph analytics solution. Through graph analytics enterprises have gained competitive advantages because they are now discovering the cause, effect, and influence of certain patterns present in their organizations data.

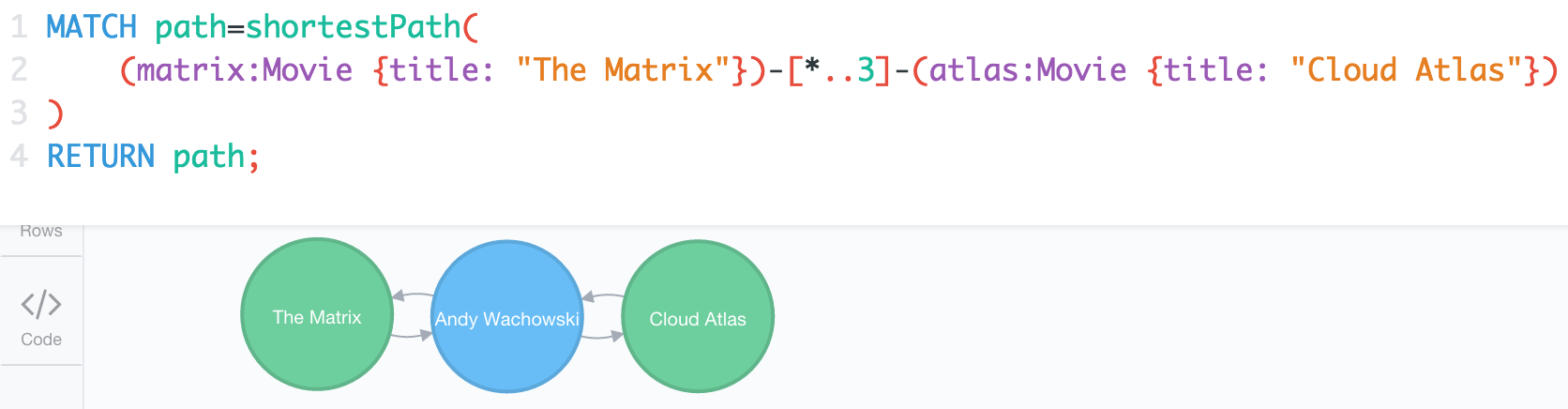
When it comes to exploring how graph analytics can be used in solving problems, it boils down to its ability to compare “many to many to many.” For example, it makes it possible to not only ask about “friends” of a person, but also friends of their friends as well with details include beyond the fact they’re connected. Building up on such scenarios allows you to see influencers within a network. Graph analytics can infer paths via complex relationships to determine connections that aren’t easy to find and surface these to human analysts for confirmation, validation and action.
Graph Analytics: Connected Data Discovery and Business Impact
One aspect where graph analytics is an advantage is data discovery. It allows you to see patterns within data when you have no idea what question you want to ask. This makes it possible to find a needle in a haystack. As patterns start emerging from data sets, you are able to surface a clear picture of the precise elements andRead More......