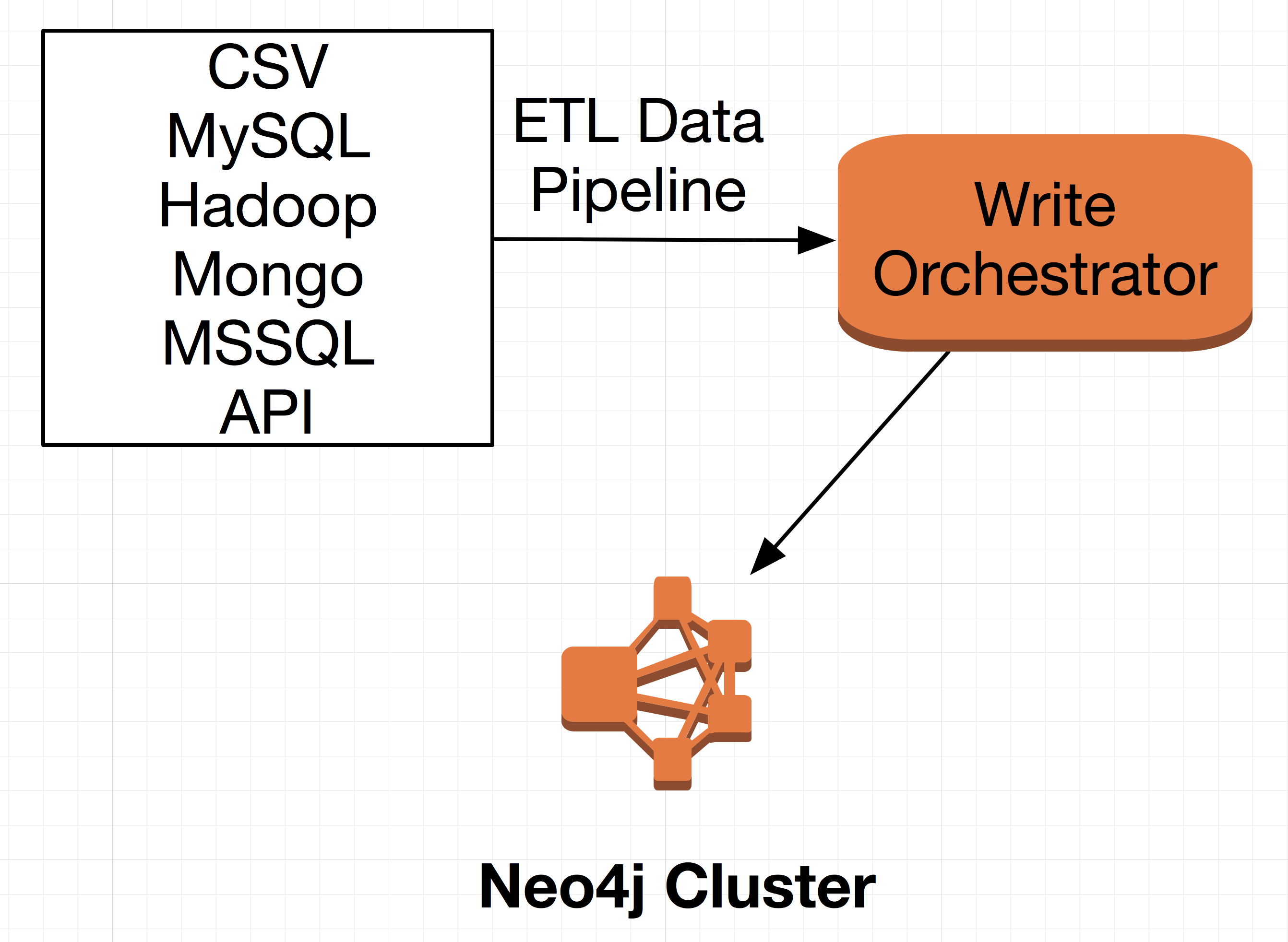
Every enterprise has a constant flow of new data that needs to be processed and stored, which can be done effectively using a data pipeline. Upon introducing Neo4j into an enterprise data architecture it becomes necessary to efficiently transform and load data into the Neo4j graph database. Doing this efficiently at scale with the enterprise integration patterns involved requires an intimate understanding of Neo4j write operations along with routing and queuing frameworks such as Apache Camel and ActiveMQ. Managing this requirement with its complexity proves to be a common challenge from enterprise to enterprise.
One of the common needs we’ve observed over the years is that an enterprise that wants to move forward efficiently with a Neo4j graph database needs to be able to rapidly create a reliable and robust data pipeline that can aggregate, manage and write their ever increasing volumes of data. The primary reason for this is to make it possible to write data in a consistent and reliable manner at a know flow rate. Solving this once and providing a robust solution for all is the driving force behind the creation of GraphGrid Data Pipeline.
GraphGrid Data Pipeline
The GraphGrid Data Platform, offers a robust data pipeline that manages high write throughput to Neo4j from varying input sources. The data pipeline is capable of batch operations management, keeps highly connected writes, manages data throttling, and carries out error handling processes.Concurrent Write Operation Management
GraphGrid’s data pipeline handles concurrent write operations for any incoming data via strategies involving preservation of transactional integrity and transaction batch sizing and data throttling. A majority of writes to Neo4j work well for concurrent write operations, but in scenarios where dense nodes are involved sequential strategies can be utilized to avoid excessive write retry processes. The data pipeline alsoRead More......